
Cohere 推出多模态人工智能搜索模型Embed 3,这一创新旨在释放图像数据背后的真正业务价值。Embed 3 通过将输入的数据转换成能表达其意义的向量形式来达成目标,识别相似性和差异性。该模型能够在统一的空间内处理文本和图像数据,允许用户在综合数据库中管理这两种类型的信息,这种方法极大地简化了操作流程。除了具备卓越的准确性和用户友好性之外,Embed 3 还继承了前代产品的强大企业级搜索功能。借助 Embed 3 的先进功能,企业可以有效地挖掘存储在图像中的海量数据,构建高效准确的搜索系统,从而提升员工的工作效率。https://cohere.com/blog/multimodal-embed-3
SpaceX再创历史,成功完成首次私人太空行走任务
在人类向太空探索的历史上,2024 年 9 月 12 日注定将成为一个值得纪念的日子。
这一天,美国太空探索技术公司 SpaceX 的“北极星黎明”(Polaris Dawn)任务成功实现了世界首次商业太空行走,两名平民宇航员进入了太空,为私人太空探索领域树立了新的里程碑。
“北极星黎明”任务于当地时间 9 月 10 日从美国国家航空航天局(NASA,National Aeronautics and Space Administration)肯尼迪航天中心的 39A 发射台起飞,这个发射台曾见证了阿波罗 11 号登月任务的启程。

图|执行此次任务的航天员(来源:SpaceX)
四名宇航员乘坐“韧性号”(Resilience)龙飞船,搭乘猎鹰 9 号火箭升空。
任务指挥官贾里德·艾萨克曼(Jared Isaacman)、飞行员斯科特·基德·波特(Scott Kidd Poteet),以及来自 SpaceX 的任务专家萨拉·吉利斯(Sarah Gillis)和安娜·梅农(Anna Menon),组成了这支全部由平民组成的宇航团队。
图|龙飞船外面的地球(来源:SpaceX)
在发射后的 15 小时内,“北极星黎明”就创造了自阿波罗计划以来的最高轨道高度纪录。
飞船达到了 1400.7 千米的高度,超过了之前由 NASA“双子星”11 号保持的 1373 千米的记录。这一成就不仅展示了 SpaceX 的技术实力,也为未来的深空探索任务树立了标杆。
随后在美东时间 9 月 12 日,“北极星黎明”任务进行了这次划时代的太空行走。艾萨克曼和吉利斯先后走出龙飞船,成为首批进行商业太空行走的平民宇航员。太空行走开始于早上 6 点 12 分,并持续 1 小时 46 分钟。

图|艾萨克曼出舱进行太空行走(来源:SpaceX)
艾萨克曼在太空行走期间感叹道:“SpaceX,虽然地球上还有很多工作等着我们去完成,但从这里看,地球就像一个完美的世界。”
他对地球的敬畏之心和对任务的激动之情溢于言表。
为了实现这次太空行走,SpaceX 开发了一系列专门的硬件设备,包括新型太空服、“天行者”舱门和新的激光通信系统。
SpaceX 设计了轻便灵活且能够抵御恶劣太空环境的新型太空服。一位 SpaceX 太空服工程师将其描述为“用织物制成的盔甲”,这种太空服不仅用于本次任务,还可能成为未来火星探索任务的基础。

图|出舱活动服的渲染图(来源:SpaceX)
龙飞船被大改,其国际空间站对接口被一个专门设计的“天行者”(Skywalker)舱门所取代。这个舱门配备了梯子、扶手和脚蹬,方便宇航员在飞船外部移动。
该任务还测试了一种新的通信系统,利用激光与 SpaceX 的星链卫星网络连接。艾萨克曼对媒体表示,这一系统有望为龙飞船、星际飞船或其他卫星、望远镜开辟一条全新的通信途径。
除了技术验证,“北极星黎明”任务还进行了 36 项不同的科学实验,这些实验由 31 个机构提供。
其中,一些实验将为 NASA 的人类研究计划提供数据,帮助科学家更好地理解人体如何应对太空飞行。
这些实验涵盖了广泛的领域,包括测试可穿戴设备收集生物识别数据、尝试缓解晕动症、研究微重力环境下的眼部健康,以及探索地球范艾伦辐射带对人体的影响。
NASA 人类研究项目副首席科学家詹西·麦克菲(Jancy McPhee)强调:“每次任务,无论是商业的还是 NASA 的,都为我们提供了至关重要的机会,帮我们更好地了解太空飞行如何影响人类健康。
从‘北极星黎明’任务收集的信息,将为 NASA 规划更深入的月球和火星探索提供重要见解。”

图|太空行走渲染图(来源:SpaceX)
“北极星黎明”任务是艾萨克曼资助的第二次私人 SpaceX 任务。第一次是 2021 年 9 月的“灵感 4 号”(Inspiration4)任务,那是首次由非职业宇航员组成的载人轨道飞行任务。
这两次任务都使用了“韧性号”龙飞船,并为美国圣犹大儿童研究医院筹集资金。
艾萨克曼在任务前公开表示:“这是鼓舞人心的一件事……与过去 20、30 年所见的不同的东西都会让人兴奋,思考‘如果这是今天的样子,我很想知道明天或一年后会是什么样子。’”
这次太空行走任务的成功不仅展示了 SpaceX 在私人太空探索领域的领导地位,也为未来的深空任务,特别是火星探索探索铺平了道路。
通过测试新型太空服、高轨道飞行和太空行走,SpaceX 正在积累宝贵的经验,这些经验对于未来更长时间、更远距离的深空探索任务至关重要。
此次任务计划于第六天返回地球,“韧性号”飞船将在美国佛罗里达海岸附近的几个潜在着陆区之一降落。
一艘回收船将接应飞船和宇航员,以期作为这次几十年来最具挑战的载人太空飞行任务的最后一站。
参考资料:
https://www.space.com/spacex-polaris-dawn-first-private-spacewalk
分享一个Go开发的搜索引擎-Go-Found
GoFound 是一个golang实现的全文检索引擎 基于平衡二叉树+正排索引、倒排索引实现 可支持亿级数据,毫秒级查询。 使用简单,使用http接口,任何系统都可以使用。
GoFound 一个golang实现的全文检索引擎,支持持久化和单机亿级数据毫秒级查找。
接口可以通过http调用。
详见 API文档
示例
编译好的下载地址: https://github.com/newpanjing/gofound/releases
将编译后的gofound文件复制到/usr/local/bin目录下,然后在命令行中运行gofound命令即可。
gofound --addr=:5678 --data=./data
启动成后,就可以调用API来进行索引和查询了。
在线体验
Simple社区使用的GoFound,可以直接模糊搜索相关帖子
GoFound在线管理后台Demo
http://119.29.69.50:5678/admin
QQ交流群
二进制文件下载
支持Windows、Linux、macOS、(amd64和arm64)和苹果M1 处理器
技术栈
- 二分法查找
- 快速排序法
- 倒排索引
- 正排索引
- 文件分片
- golang-jieba分词
- leveldb
为何要用golang实现一个全文检索引擎?
- 正如其名,
GoFound去探索全文检索的世界,一个小巧精悍的全文检索引擎,支持持久化和单机亿级数据毫秒级查找。 - 传统的项目大多数会采用
ElasticSearch来做全文检索,因为ElasticSearch够成熟,社区活跃、资料完善。缺点就是配置繁琐、基于JVM对内存消耗比较大。 - 所以我们需要一个更高效的搜索引擎,而又不会消耗太多的内存。 以最低的内存达到全文检索的目的,相比
ElasticSearch,gofound是原生编译,会减少系统资源的消耗。而且对外无任何依赖。
安装和启动
下载好源码之后,进入到源码目录,执行下列两个命令
- 编译
直接下载 可执行文件 可以不用编译,省去这一步。
go get && go build
- 启动
./gofound --addr=:8080 --data=./data
- docker部署
docker build -t gofound . docker run -d --name gofound -p 5678:5678 -v /mnt/data/gofound:/usr/local/go_found/data gofound:latest
- 其他命令 参考 配置文档
多语言SDK
使用gofound的多语言SDK,可以在不同语言中使用gofound。但是请注意,版本号与gofound需要一致。主版本和子版本号,修订版不一致不影响。
其他语言的SDK,正在陆续完善中。也可以直接通过API文档用HTTP请求实现。
和ES比较
| ES | GoFound |
|---|---|
| 支持持久化 | 支持持久化 |
| 基于内存索引 | 基于磁盘+内存缓存 |
| 需要安装JDK | 原生二进制,无外部依赖 |
| 需要安装第三方分词插件 | 自带中文分词和词库 |
| 默认没有可视化管理界面 | 自带可视化管理界面 |
| 内存占用大 | 基于Golang原生可执行文件,内存非常小 |
| 配置复杂 | 默认可以不加任何参数启动,并且提供少量配置 |
待办
利用 cloudflare flexible ssl实现wordpress全站强制https
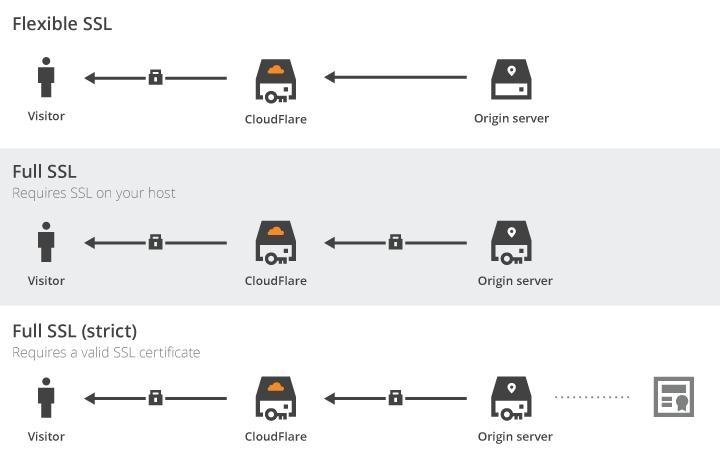
个人网站需要https加密。要实现https功能,一种方法是购买证书,当然现在也可以申请到免费证书,但前提是空间要支持自有证书。另外一种方式比较简单,就是利用cloudflare的flexible ssl功能,实现wordpress全站强制https。
原理很简单:
- 利用cloudflare的CDN功能,让cloudflare充当客户端与wordpress hosting之间的缓冲。
- 开启cloudflare的flexible ssl功能,使客户端与cloudflare缓冲之间的通讯流量加密。
具体的步骤如下:
1、申请cloudflare账号,此步略。
2、在cloudflare上添加域名,如我的域名luluck.com。
3、cloudflare会自动扫描添加的域名,显示该域名的A,CNAME records等。如扫描不出,自己添加。
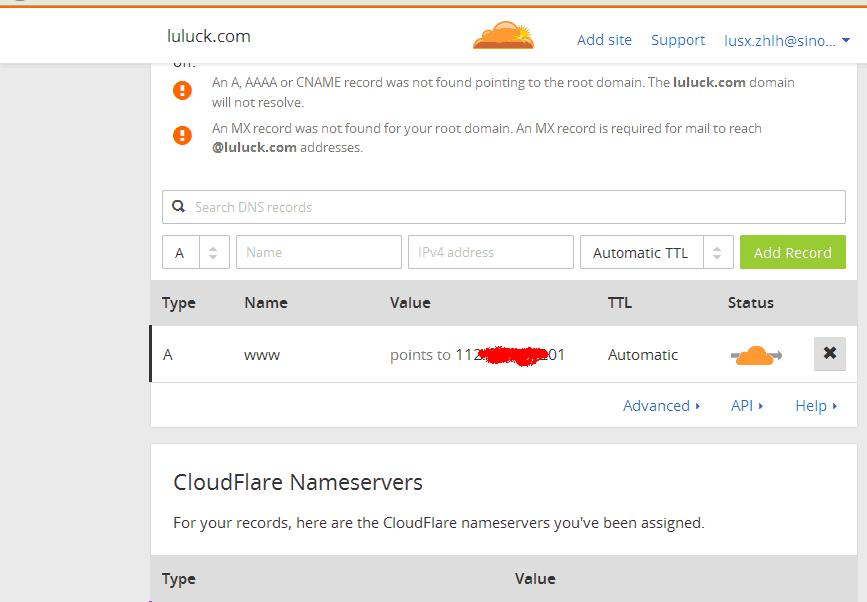
4、在域名提供商处更改DNS服务器,如我的namesilo,将原域名商的DNS服务器更改为cloudflare提供的DNS服务器。
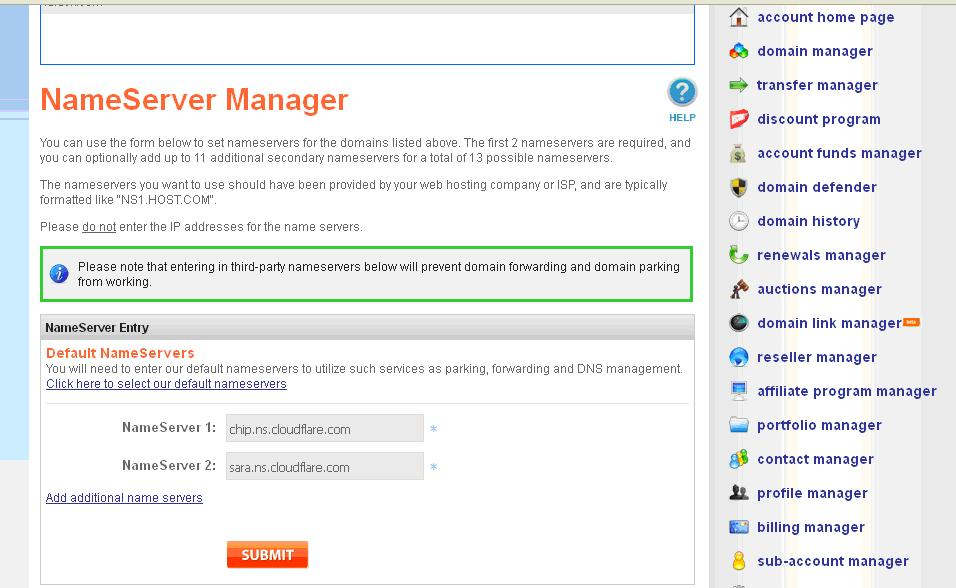
5、在crypto页面中,SSL开启flexible。
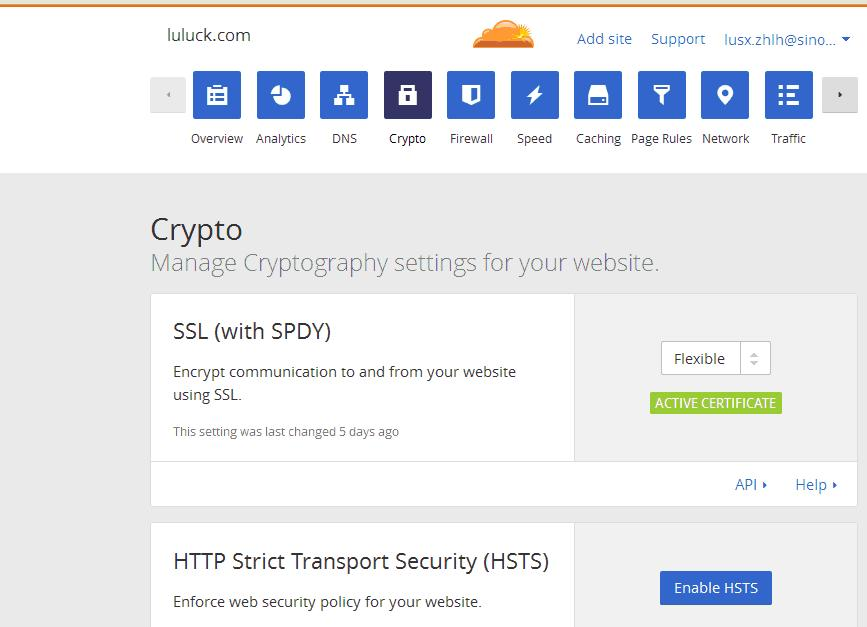
6、在page rules页面中,添加规则:http://www.luluck.com/*,always uses https。使客户端的http访问强制为https访问。
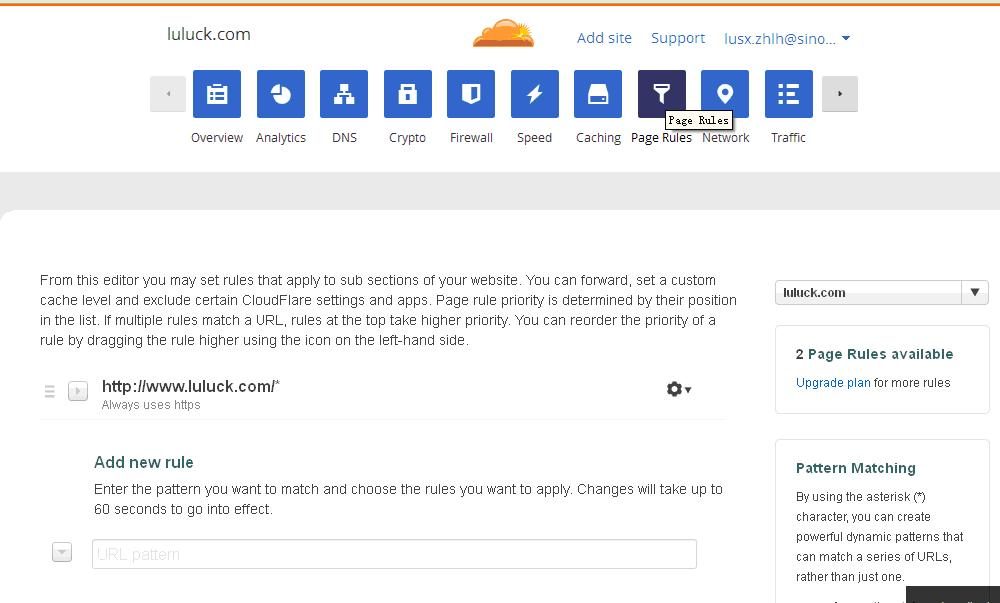
7、修复cloudflare ssl flexible的the infinite redirect loop error问题:
① 安装wordpress的CloudFlare Flexible SSL WordPress plugin插件(resolve redirect loop issues)。
②安装wordpress的CloudFlare WordPress plugin插件(make sure that the original visitor IP is being passed back at the WordPress level.)。
注意:以上DNS转移生效比较滞后,需要一段时间才会测试正常。
OK,完成。
后注:XP下ie和chrome访问好像有问题,chrome显示“A secure connection cannot be established because this site uses an unsupported protocol.”,而firefox访问正常。win7下三种浏览器均正常。
值得关注的12个很赞的移动开发框架
1. Redbeard
Redbeard makes it faster and easier to create native apps without a boilerplate. It’s a complete framework with tons of components.There’s a whole variety of ready to use components for some of the most commonly needed functionality. Every component is fully themable via our awesome theming engine. No need for wrapper apps or wrapper frameworks. Redbeard is fully 100% native development framework that works with Objective-C and Swift across the whole iOS suite.
2. Weex
Weex is a mobile cross-platform UI framework. It’s lightweight, high-performance, and extendable. Weex is from Alibaba to build mobile apps with just HTML, CSS and JavaScript. It comes with Modules, UI components, its own DevTools and CLI that is designed towards mobile environment and to speed up development.
3. Rikulo
Rikulo UI is a Dart framework for creating cross-platform web and native mobile applications with HTML5. It uses a structured UI model and offers a responsive UX across desktop & touch devices.
4. A Frame

A-Frame is a framework for building things for the virtual reality web. You can use markup to create VR experiences that work across desktop, iPhones, and the Oculus Rift.
5. Onsen UI
Onsen UI is a mobile framework that includes Javascript and CSS frameworks for HTML5, PhoneGap & Cordova apps. It offers a large selection of Web-based UI components, and responsive layouts for smartphones and tablets, among other features.
6. Tabris.js
Tabris.js is a mobile framework that makes it simple to create native apps for iOS and Android in JavaScript. It doesn’t use WebViews for rendering UI, and instead creates native widgets on the mobile platform via a JavaScript-to-native bridge. This also enables the quick develop / deploy cycle that you know from web development.
7. Rad.js

RAD.js is the solution to the problem of creating apps with multiplatform capabilities and native-like responsiveness, performance, and usability. It is a toolkit created by MobiDev experts for business needs of mobile startups, well-established businesses, and directly for software developers.
8. Konva
Kanva is a 2D HTML5 canvas framework for creating desktop and mobile apps. It has an object oriented API, layering support, tween and animation support, filters, and custom shapes, among other features.
9. Mootor
Mootor is an HTML5 framework for developing mobile apps. It’s minimalist and works on multiple platforms, including iOS, Android, and others.
10. TouchstoneJS
TouchstoneJS is a UI framework powered by React.js for developing hybrid mobile apps. It includes form components, navigation, transitions, native touch behaviors, and much more, with more features on the way.
11. Pikabu
Pikabu is a framework for creating off-canvas flyout panels. It has simple markup, supports native scrolling, and is fully customizable.
12. Clank
Clank is an open source HTML and CSS framework for prototyping native mobile and tablet apps. It uses modern CSS techniques, with Sass and Compass, and its component based so you can pick and choose what you need.
【伪正版】Sublime Text 3截止2019.04.08最新版本破解 3207
Sublime Text 3最近更新了版本,最新版本:3207,之前的license无效了,然后在GitHub找到最新的破解方法

本方法适用:Sublime Text Version 3.2.1, Build 3207
安装sublime text3
下载地址:https://www.sublimetext.com/3
根据你系统的版本下载安装
修改sublime text 3 exe程序
- 进入:https://hexed.it/
- 点击“Open file”,然后选择“sublime_text.exe”(ps. sublime_text.exe应该在:C:\Program Files\Sublime Text 3)
- 选择右侧的“Search”,然后在“Search for”框输入“97 94 0D”,点击“Search Now”

- 下方出现一个搜索结果
- 点击搜索结果,修改搜索结果“97 94 0D”为“00 00 00”
- 点击“Export”把修改好的exe程序下载并替换原来的sublime_text.exe
- 打开sublime text3 (如果windows提示危险,继续运行),然后Help-Enter License-输入下方的license
----- BEGIN LICENSE -----
TwitterInc
200 User License
EA7E-890007
1D77F72E 390CDD93 4DCBA022 FAF60790
61AA12C0 A37081C5 D0316412 4584D136
94D7F7D4 95BC8C1C 527DA828 560BB037
D1EDDD8C AE7B379F 50C9D69D B35179EF
2FE898C4 8E4277A8 555CE714 E1FB0E43
D5D52613 C3D12E98 BC49967F 7652EED2
9D2D2E61 67610860 6D338B72 5CF95C69
E36B85CC 84991F19 7575D828 470A92AB
------ END LICENSE ------
- 最后,为了防止sublime text3检测,添加以下内容到你的host
127.0.0.1 www.sublimetext.com
127.0.0.1 sublimetext.com
127.0.0.1 sublimehq.com
127.0.0.1 telemetry.sublimehq.com
127.0.0.1 license.sublimehq.com
127.0.0.1 45.55.255.55
127.0.0.1 45.55.41.223
0.0.0.0 license.sublimehq.com
0.0.0.0 45.55.255.55
0.0.0.0 45.55.41.223
ps. windows的hosts文件大致在:C:\Windows\System32\drivers\etc
至此,sublime text 3207破解完毕
搭了个gitlab
今天无意中看见个CN2线路,2核+4GB+4T的VPS,打了下折之后年付18美元。这么便宜,我都不敢把服务商写出来了。当然这是OpenVZ的,目前看来还好,将来不知道会被玩坏成什么样子。
开源的自建git项目托管服务,貌似有模仿github用ruby写的gitlab,用scala基于JVM的GitBucket,以及国人用golang开发的gogs/gitea等。功能最完善的当然是gitlab了。 gogs可以跑在路由器、树莓派等低配置硬件上,听闻国内有小团队直接用树莓派挂块硬盘跑gogs作为公司的代码仓库。至于GitBucket,没试过,猜想应该具有Java一贯的容易部署高内存消耗的特性吧。
之前想装gitlab,都被官方文档的推荐内存要求吓退,最终都换成了gitea/gogs。虽然kvm可以通过swap加大内存绕过,但是好像比较卡,所以都没怎么用过。
成果
测试了下搭建私有gitlab带Web-IDE的持续集成环境。
目前能做到在gitlab网页上编辑一下文件或者本地编辑后push一下,会自动触发gitlab-runner(一个docker虚拟机环境),进行自动的编译和测试工作。如果编译与测试均成功通过,则进行部署。这样简化软件开发流程。
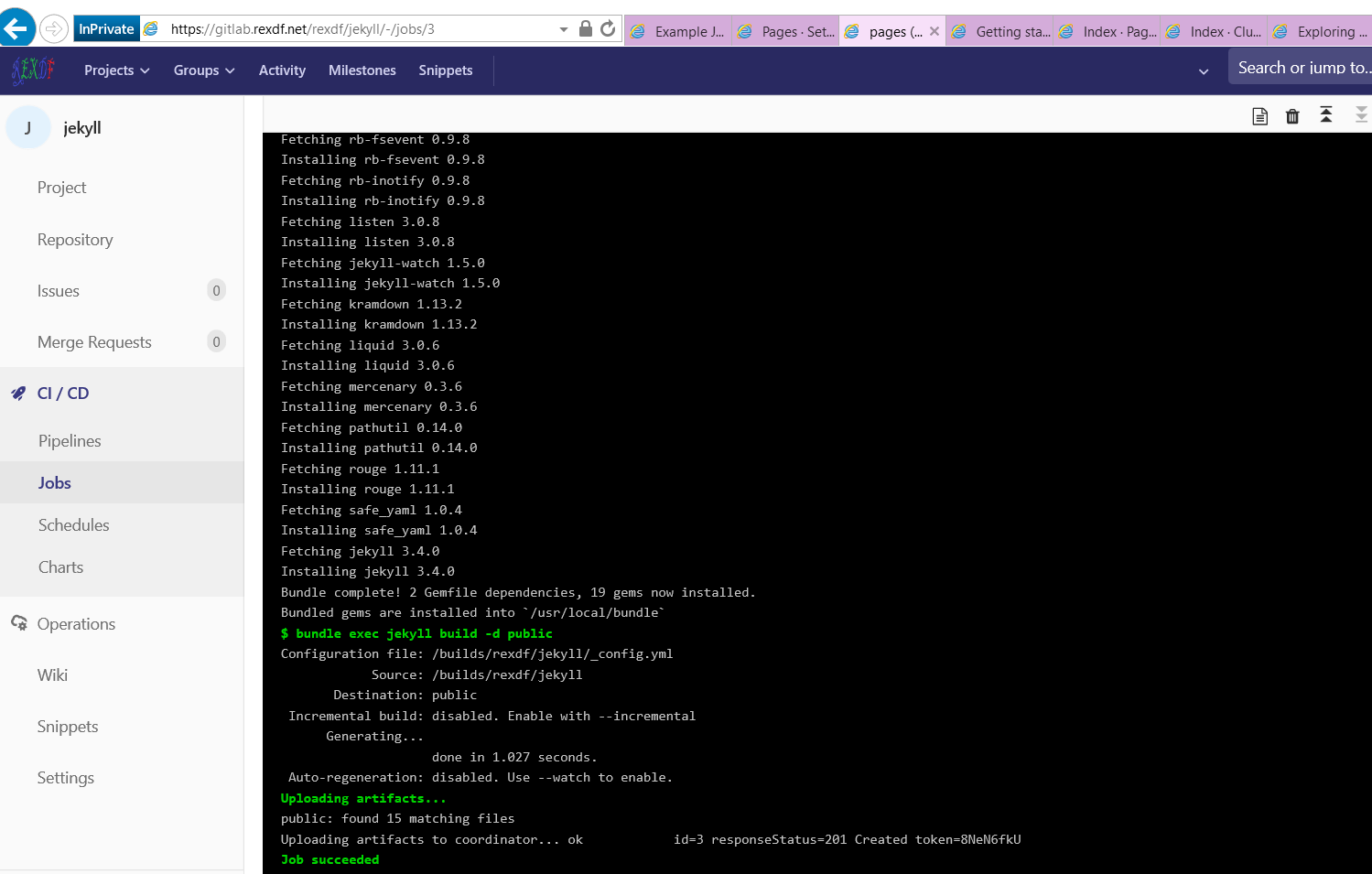
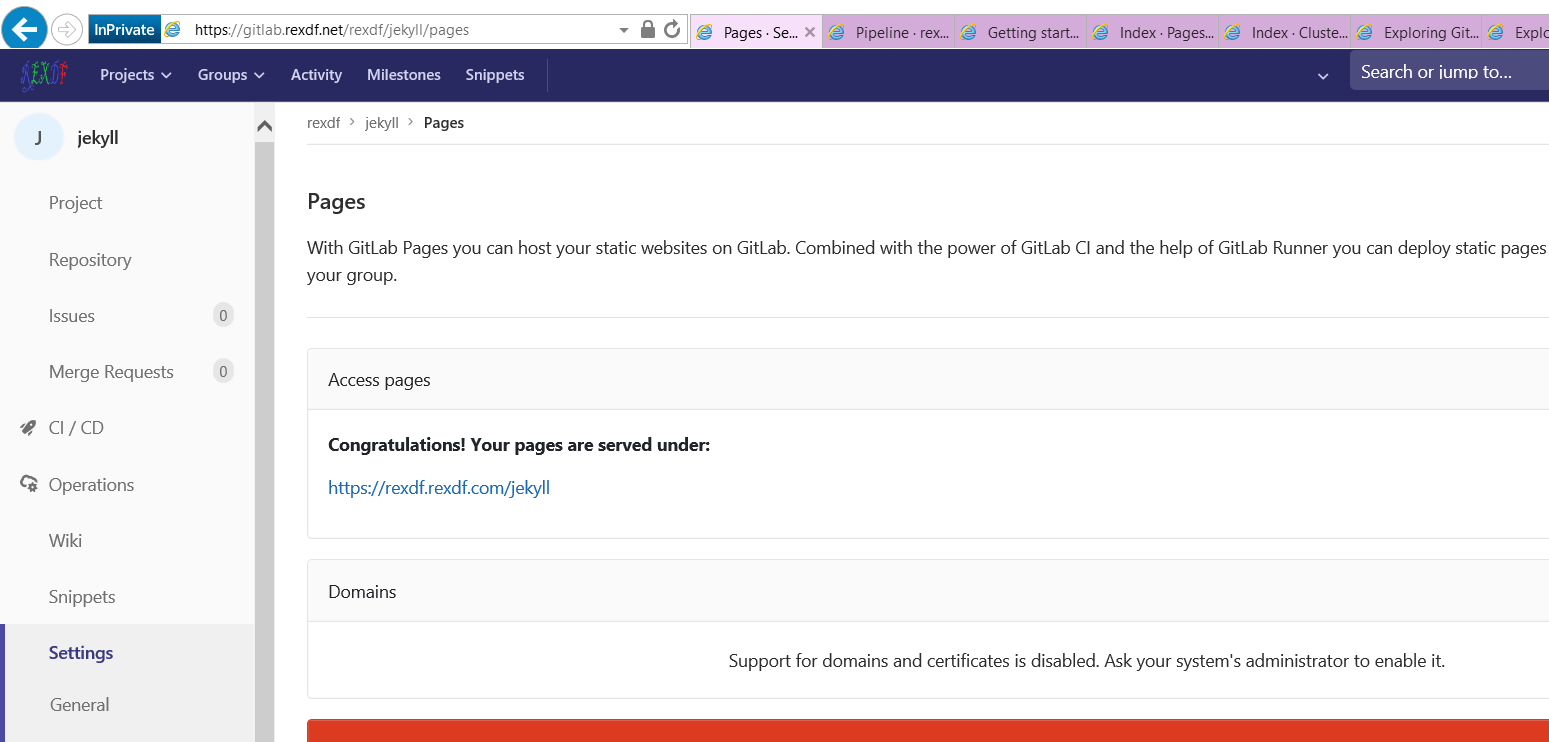
如下四张图
Pipelines & Jobs
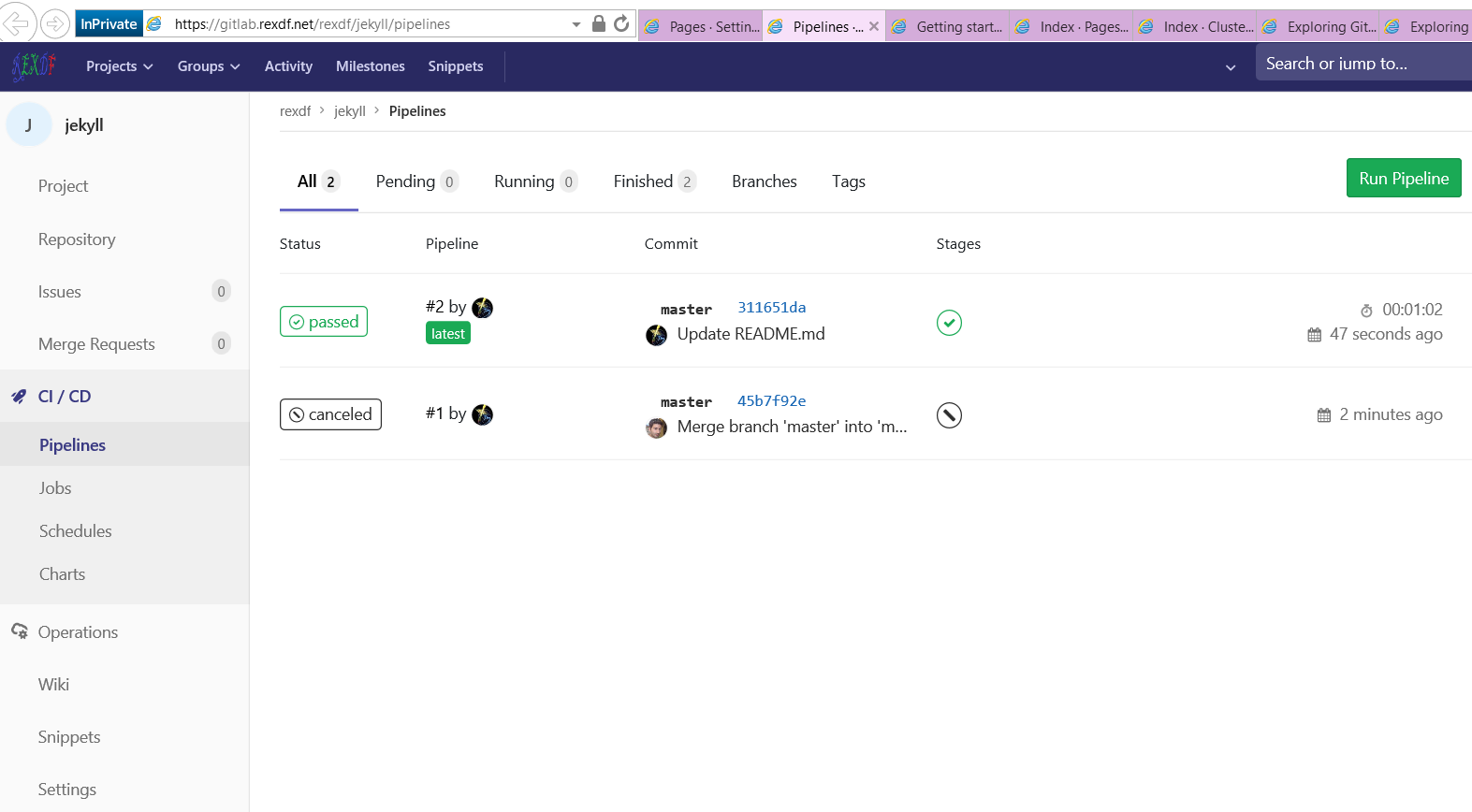
GitLab Pages
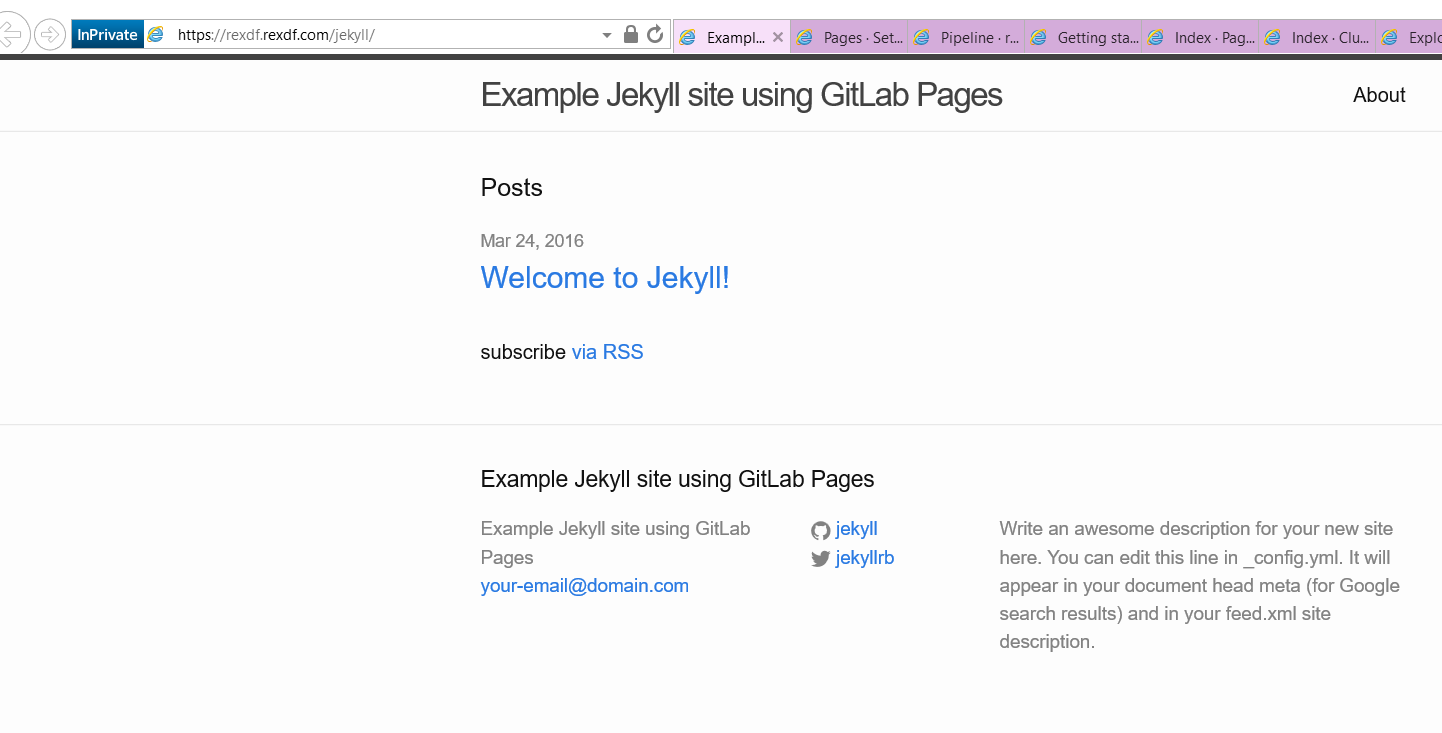
安装
登录系统初始设置
我的惯例是如下,首先禁掉密码登录(nano /etc/ssh/sshd_config),然后更新(apt-get update && apt-get -y upgrade),重启(reboot)
安装常用软件配置等
这里只随手打一下习惯性手指条件反射记得的包
|
apt-get install curl wget bash-completion git bmon htop iftop nano vnstat build-essential language-pack-zh-hans
locale-gen zh_CN.UTF-8
|
安装gitlab依赖
按照我一贯的习惯,能用包管理,尽量用包管理,docker次之,最次脚本安装。直接按照官方文档就好。
|
sudo apt-get update
sudo apt-get install -y curl openssh-server ca-certificates postfix
|
安装gitlab
之前有玩过bitnami的虚拟机版本gitlab,那个是GitLab CE。然而GitLab官方在这里说GitLab Enterprise Edition版本具有社区版本(MIT Expat license)的全部功能,而且能随时使用商业版以及试用过期后回退到社区版。故而直接安装企业版。
|
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ee/script.deb.sh | sudo bash
|
先加入GitLab官方的源,并导入密钥。
现在去设置一下dns,把域名指向过来。然后就可以通过包管理来安装了
|
sudo EXTERNAL_URL=“https://gitlab.rexdf.net” apt-get install gitlab-ee
|
小插曲:安装过程中会自动设置letsencrypt证书,我预想的是只是配置而已,然而当我看到letsencrpt字样的dpkg error时,就发现了这安装程序原来集成了自动配置证书功能。
用户配置
打开网页就是一个密码输入界面,这里输入的是GitLab的root用户的密码。然后注册了一个普通用户,发现没有任何验证,赶紧用root用户管理员关掉任意用户注册功能。
配置CI/CD
我并没有配置太多,只是换了下favicon与logo,然后用普通权限用户的ssh实验了下private项目的pull与push。 具体过程和github与Gitbucket没啥区别,这里不赘述。 当然修改gitlab.rb之后gitlab-ctl reconfigure这个应该也是要养成习惯了。
自定义域名的GitLab Pages服务
默认是没有开启Pages服务的。由于有点想当做博客/维基用的想法,所以研究了下。也挺简单,参考官方文档,一小时搞定。
首先要泛解析另外一个域名,出于防范XSS攻击考虑,官方不推荐用gitlab服务的主域名。而且gitlab的安装程序目前似乎还不能自动配置泛解析letsencrypt证书。
Let’s Encrypt支持泛解析测试的时候就看到过尝鲜用户的报告。印象中acme.sh是支持得最好的。我用的是如下的指令
|
#安装acme.sh(会自动配置alias和crontab等)
curl https://get.acme.sh | sh
#通过环境变量传递DNSPOD的api key
export DP_Id=“123456”
export DP_Key=“14axxxxxbccxxxxx8a25xxxxx6xxxxx9”
#用上面的环境变量签泛解析证书
acme.sh –issue -d ‘*.rexdf.com’ –dns dns_dp
#把证书拷贝到gitlab配置目录下
acme.sh –installcert -d ‘*.rexdf.com’ \
–key-file /etc/gitlab/ssl/rexdf.com.pages.key \
–fullchain-file /etc/gitlab/ssl/rexdf.com.pages.crt
|
然后修改/etc/gitlab/gitlab.rb
找到gitlab pages相关的地方 最终如下
|
pages_external_url “https://rexdf.com/”
gitlab_pages[‘enable’] = true
pages_nginx[‘redirect_http_to_https’] = true
pages_nginx[‘ssl_certificate’] = “/etc/gitlab/ssl/rexdf.com.pages.crt”
pages_nginx[‘ssl_certificate_key’] = “/etc/gitlab/ssl/rexdf.com.pages.key”
|
配置GitLab Runner
虽然有openvz官方的这篇说明openvz是可以支持docker的,然而我的这个好像不支持,下单时我应该选3.x kernel的。 不过还好gitlab-runner好像就不推荐和gitlab跑在同一个机器上。
在另外一台也是极端便宜的小鸡上装了个gitlab-runner
安装docker
参考docker官方文档
|
apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add –
sudo add-apt-repository \
“deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable”
apt-get update
sudo apt-get install docker-ce
|
安装gitlab-runner及其配置
参考官方文档
|
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | sudo bash
sudo apt-get install gitlab-runner
|
配置相对来说比较方便,Runner executor选docker,然后镜像选择ruby:2.3就好了
|
sudo gitlab-runner register
|
另外gitlab-runner配置在/etc/gitlab-runner/config.toml
错误
|
This job is stuck, because you don’t have any active runners that can run this job.
|
应该在runner上面勾选Run untagged jobs [] Indicates whether this runner can pick jobs without tags
时间成本
看了下付款记录,11点付款,下午2点多开始想搭gitlab,到现在写完本文下午6点钟。 整体上比较简单,只要照着官方文档复制粘贴命令就好了。
维护
2018年10月2日
今天好像Debian系列的libc都升级了,于是惯例升级下系统。然而gitlab这次遇到了点儿问题记录下。
问题
|
apt-get update && apt-get -y dist-upgrade
Get:1 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB]
…
Get:17 http://archive.ubuntu.com/ubuntu xenial-updates/universe Translation-en [279 kB]
Fetched 3,792 kB in 2s (1,377 kB/s)
Reading package lists… Done
Reading package lists… Done
Building dependency tree
Reading state information… Done
Calculating upgrade… Done
The following packages will be upgraded:
gitlab-ee linux-libc-dev
2 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
Need to get 494 MB of archives.
After this operation, 1,921 kB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu xenial-updates/main amd64 linux-libc-dev amd64 4.4.0-137.163 [850 kB]
Get:2 https://packages.gitlab.com/gitlab/gitlab-ee/ubuntu xenial/main amd64 gitlab-ee amd64 11.3.1-ee.0 [493 MB]
Fetched 494 MB in 15s (32.8 MB/s)
(Reading database … 118431 files and directories currently installed.)
Preparing to unpack …/linux-libc-dev_4.4.0-137.163_amd64.deb …
Unpacking linux-libc-dev:amd64 (4.4.0-137.163) over (4.4.0-135.161) …
Preparing to unpack …/gitlab-ee_11.3.1-ee.0_amd64.deb …
gitlab preinstall: Automatically backing up only the GitLab SQL database (excluding everything else!)
Dumping database …
Dumping PostgreSQL database gitlabhq_production … [DONE]
done
Dumping repositories …
[SKIPPED]
Dumping uploads …
[SKIPPED]
Dumping builds …
[SKIPPED]
Dumping artifacts …
[SKIPPED]
Dumping pages …
[SKIPPED]
Dumping lfs objects …
[SKIPPED]
Dumping container registry images …
[DISABLED]
Creating backup archive: 1538469788_2018_10_02_11.3.0-ee_gitlab_backup.tar … done
Uploading backup archive to remote storage … skipped
Deleting tmp directories … done
done
Deleting old backups … skipping
Unpacking gitlab-ee (11.3.1-ee.0) over (11.3.0-ee.0) …
dpkg: error processing archive /var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb (–unpack):
unable to stat other new file ‘/opt/gitlab/embedded/postgresql/9.6.8/share/extension/lo–1.0–1.1.sql’: Cannot allocate memory
Errors were encountered while processing:
/var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
如果继续运行 apt-get update && apt-get -y dist-upgrade 则是类似如下的错误
|
dpkg: error processing archive /var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb (–unpack):
unable to stat ‘./opt/gitlab/embedded/lib/ruby/gems/2.4.0/gems/graphql-1.8.1/spec/dummy/tmp/cache/assets/sprockets/v3.0/ij/ijLUBXXLleeHIaUQp-SQmpq0HpA44rYlbW5OJbKpnsg.cache’ (which I was about to install): Cannot allocate memory
dpkg-deb: error: subprocess paste was killed by signal (Broken pipe)
Errors were encountered while processing:
/var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
探索
期初我以为是内存的原因,于是/opt/gitlab/bin/gitlab-ctl status 然后 /opt/gitlab/bin/gitlab-ctl stop以及/opt/gitlab/bin/gitlab-ctl start postgresql和/opt/gitlab/bin/gitlab-ctl start postgres-exporter。这样内存占用减小到了206M/4G,而且开了另外一个终端实时监控内存使用情况,发现运行dpkg -i /var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb过程中,内存从来就没超过1G。于是基本否定内存不足的情况了。
解决
运行如下三条命令即可解决
|
xx:~# apt-get install -f
Reading package lists… Done
Building dependency tree
Reading state information… Done
The following packages will be REMOVED:
gitlab-ee
0 upgraded, 0 newly installed, 1 to remove and 0 not upgraded.
2 not fully installed or removed.
After this operation, 1,524 MB disk space will be freed.
Do you want to continue? [Y/n]
(Reading database … 118428 files and directories currently installed.)
Removing gitlab-ee (11.3.0-ee.0) …
Setting up linux-libc-dev:amd64 (4.4.0-137.163) …
xx:~# dpkg -i /var/cache/apt/archives/gitlab-ee_11.3.1-ee.0_amd64.deb
xx:~# gitlab-ctl restart
|
真实原因
老版本依然在运行中,而且没有卸载。所以新版本无法覆盖。
Caddy – 方便够用的 HTTPS server 新手教程
说起 HTTP server,使用最广泛的就是 apache 和 nginx 了,功能都非常强大,但相对而言,学习它们的配置是有一定难度的。最近发现了一个 golang 开发的 HTTP server,叫做 Caddy,它配置起来十分简便,甚至可以 28 秒配置好一个支持 http2 的 server ,而且对各种 http 新特性都支持的比较早(比如 http2、quic都有支持)。因此对于不用于生产环境只搭建个人博客是十分友好的,我就简单介绍下 caddy。
Caddy – 方便够用的 HTTPS server 新手教程
aa
1. 安装
用过 golang 的应该都知道,golang 程序基本上不会有各种依赖,都是光秃秃一个可执行程序,cp 到 /usr/local/bin就算安装完成了,所以说安装 caddy 是很简单的,我给出三种方法。
1.1 脚本安装
curl -s https://getcaddy.com | bash
caddy 官方给出了一个安装脚本,执行上面的命令就可以一键安装 caddy,等执行结束后,使用 which caddy,可以看到 caddy 已经被安装到了 /usr/local/bin/caddy
1.2 手动安装
https://caddyserver.com/download 点这个链接进入到 caddy 官网的下载界面,网页左侧可以选择平台和插件,如果在 Linux 服务器上使用的话,platform 选择 Linux 64-bit 就可以了,plugins 如果暂时不需要的话,可以不选。然后点击下面的 DOWNLOAD 按钮,就下载到 caddy 了。同理,解压之后用 cp 命令放到 /usr/local/bin/caddy 就完成了安装。

1.3 源码安装
go get github.com/mholt/caddy/caddy
对于安装了 golang 编译器的同学,只需要执行 go get 就能到 $GOPATH/bin 里,是否 cp 到 /usr/local/bin 里就看心情了。使用源码安装可以安装到最新版本的 caddy,功能上一般是最新的,而且因为是本地编译,性能可能会稍微高一些,但是可能会存在不稳定的现象。
2. 配置
2.1 临时文件服务器
Caddy 的配置文件叫做 Caddyfile,Caddy 不强制你把配置文件放到哪个特定文件夹,默认情况下,把 Caddyfile 放到当前目录就可以跑起来了,如下:
echo 'localhost:8888' >> Caddyfileecho 'gzip' >> Caddyfileecho 'browse' >> Caddyfilecaddy
在随便一个目录里执行上面代码,然后在浏览器里打开 http://localhost:8888 发现 caddy 已经启动了一个文件服务器。当临时需要一个 fileserver 的时候(比如共享文件),使用 caddy 会很方便。
2.2 生产环境使用
当然了,在生产环境使用的时候就不能这么草率的把配置文件放到当前目录了,一般情况下会放到 /etc/caddy 里。
sudo mkdir /etc/caddysudo touch /etc/caddy/Caddyfilesudo chown -R root:www-data /etc/caddy
除了配置文件,caddy 会自动生成 ssl 证书,需要一个文件夹放置 ssl 证书。
sudo mkdir /etc/ssl/caddysudo chown -R www-data:root /etc/ssl/caddysudo chmod 0770 /etc/ssl/caddy
因为 ssl 文件夹里会放置私钥,所以权限设置成 770 禁止其他用户访问。
最后,创建一下放置网站文件的目录,如果已经有了,就不需要创建了。
sudo mkdir /var/wwwsudo chown www-data:www-data /var/www
创建好这些文件和目录了之后,我们需要把 caddy 配置成一个服务,这样就可以开机自动运行,并且管理起来也方便。因为目前大多数发行版都使用 systemd 了,所以这里只讲一下如何配置 systemd,不过 caddy 也支持配置成原始的 sysvinit 服务,具体方法看这里。
sudo curl -s https://raw.githubusercontent.com/mholt/caddy/master/dist/init/linux-systemd/caddy.service -o /etc/systemd/system/caddy.service # 从 github 下载 systemd 配置文件sudo systemctl daemon-reload # 重新加载 systemd 配置sudo systemctl enable caddy.service # 设置 caddy 服务自启动sudo systemctl status caddy.service # 查看 caddy 状态
3. Caddyfile
基本的安装配置搞定之后,最重要的就是如何写 Caddyfile了。可以直接 vim /etc/caddy/Caddyfile 来修改 Caddyfile,也可以再自己电脑上改好然后 rsync 到服务器上。如果修改了 Caddyfile 发现没有生效,是需要执行一下 sudo systemctl restart caddy.service 来重启 caddy 的。
3.1 Caddyfile 的格式
Caddfile的格式还是比较简单的,首先第一行必须是网站的地址,例如:
localhost:8080
或
lengzzz.com
地址可以带一个端口号,那么 caddy 只会在这个端口上开启 http 服务,而不会开启 https,如果不写端口号的话,caddy 会默认绑定 80 和 443 端口,同时启动 http 和 https 服务。
地址后面可以再跟一大堆指令(directive)。Caddyfile 的基本格式就是这样,由一个网站地址和指令组成,是不是很简单。
3.2 指令
指令的作用是为网站开启某些功能。指令的格式有三种,先说一下最简单的不带参数的指令比如:
railgun.moe # 没错,moe后缀的域名也可以哦gzip
第二行的 gzip 就是一个指令,它表示打开 gzip 压缩功能,这样网站在传输网页是可以降低流量。
第二种指令的格式是带简单参数的指令:
railgun.moegziplog /var/log/caddy/access.logtls lengz@lengzzz.comroot /var/www/
第三行,log 指令会为网站开启 log 功能,log 指令后的参数告诉 caddy log 文件存放的位置。第四行的 tls 指令告诉 caddy 为网站开启 https 并自动申请证书,后面的 email 参数是告知 CA 申请人的邮箱。(caddy 会默认使用 let’s encrypt 申请证书并续约,很方便吧)
另外,简单参数也可能不只一个,比如 redir 指令:
railgun.moegziplog /var/log/caddy/access.logtls /etc/ssl/cert.pem /etc/ssl/key.pemroot /var/www/redir / https://lengzzz.com/archive/{uri} 301
上面的 redir 指令带了三个参数,意思是把所有的请求使用 301 重定向到 https://lengzzz.com/archive/xxx,这个指令在给网站换域名的时候很有用。另外 tls 指令变了,不单单传 email一个参数, 而是分别传了证书和私钥的路径,这样的话 caddy 就不会去自动申请证书,而是使用路径给出的证书了。
在这个例子里还使用了 {uri} 这样的占位符(placeholder),详细的列表可以在这里查询到:https://caddyserver.com/docs/placeholders。
最后一种指令是带复杂参数的,这种指令包含可能很多参数,所以需要用一对花括号包起来,比如 header 指令:
railgun.moegziplog /var/log/caddy/access.logtls lengz@lengzzz.comroot /var/www/header /api {Access-Control-Allow-Origin *Access-Control-Allow-Methods "GET, POST, OPTIONS"-Server}fastcgi / 127.0.0.1:9000 php {index index.php}rewrite {to {path} {path}/ /index.php?{query}}
6-10 行的 header 指令代表为所有的 /api/xxx 的请求加上 Access-Control-Allow-Origin 和 Access-Control-Allow-Methods 这两个 header,从而能支持 javascript 跨域访问 ,第 9 行代表删除 Server header,防止别人看到服务器类型。
11-13 行使用了 fastcgi 指令,代表把请求通过 fastcgi 传给 php,ruby 等后端程序。
14-15 行,使用了 rewrite 指令,这个指令的作用是 服务器内部重定向 在下面的参数 to 后面,又跟了三个参数,这个功能上有点类似 nginx 的 try_files 。告诉 caddy 需要先查看网址根目录 /var/www 里有没有 {path} 对应的文件,如果没有再查看有没有 {path} 对应的目录,如果都没有,则转发给 index.php 入口文件。这个功能一般会用在 PHP 的 MVC 框架上使用。
随着一步步完善这个 Caddyfile,目前这个版本的 Caddyfaile 已经可以直接在网站中使用了。
3.3 多 HOST 网站
刚才说的一直都是单个域名的网址,那么如果在同一个服务器上部署多个域名的网站呢?很简单,只需要在域名后面跟一个花括号扩起来就可以了,如下:
railgun.moe {gziplog /var/log/caddy/railgun_moe.logtls lengz@lengzzz.comroot /var/www/header /api {Access-Control-Allow-Origin *Access-Control-Allow-Methods "GET, POST, OPTIONS"-Server}fastcgi / 127.0.0.1:9000 php {index index.php}rewrite {to {path} {path}/ /index.php?{query}}}lengzzz.com {tls lengz@lengzzz.comlog /var/log/caddy/lengzzz_com.logredir / https://railgun.moe/{uri} 301}
好了,基本的 caddy 配置就这些,详细的内容可以去官网上看文档学习。
转自: https://lengzzz.com/note/caddy-http-2-web-server-guide-for-beginners
WebSocket(叁) 生成数据帧
昨天的文章中介绍了WebSocket数据帧的结构和解析。其实对从服务器发送往客户端的数据也是同样的数据帧。但因此觉得这看似和解析数据帧一样简单那就错了。我们需要自己去生成数据帧。而且会遇上和解析时候不同的问题,比如数据帧分片传输的情况。
从服务器发送到客户端的数组帧不需要掩码,这是非常值得庆幸的地方。于是要写出一个生成数据帧的函数并不难
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | //NodeJS function encodeDataFrame(e){ var s=[],o=new Buffer(e.PayloadData),l=o.length; //输入第一个字节 s.push((e.FIN<<7)+e.Opcode); //输入第二个字节,判断它的长度并放入相应的后续长度消息 //永远不使用掩码 if(l<126)s.push(l); else if(l<0x10000)s.push(126,(l&0xFF00)>>8,l&0xFF); else s.push( 127, 0,0,0,0, //8字节数据,前4字节一般没用留空 (l&0xFF000000)>>24,(l&0xFF0000)>>16,(l&0xFF00)>>8,l&0xFF ); //返回头部分和数据部分的合并缓冲区 return Buffer.concat([new Buffer(s),o]); }; |
可以把它用于一个实例中
1 2 3 4 5 | //客户端程序 var ws=new WebSocket("ws://127.0.0.1:8000/"); ws.onmessage=function(e){ console.log(e); }; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | //服务器程序 var crypto=require('crypto'); var WS='258EAFA5-E914-47DA-95CA-C5AB0DC85B11'; require('net').createServer(function(o){ var key; o.on('data',function(e){ if(!key){ //握手 key=e.toString().match(/Sec-WebSocket-Key: (.+)/)[1]; key=crypto.createHash('sha1').update(key+WS).digest('base64'); o.write('HTTP/1.1 101 Switching Protocols\r\n'); o.write('Upgrade: websocket\r\n'); o.write('Connection: Upgrade\r\n'); o.write('Sec-WebSocket-Accept: '+key+'\r\n'); o.write('\r\n'); //握手成功后给客户端发送个数据 o.write(encodeDataFrame({ FIN:1,Opcode:1,PayloadData:"次碳酸钴" })); }; }); }).listen(8000); |
上面是最基本的用法。但是有时候数据需要分成多个数据包来发送,这就需要用到分片,也就是使用多个数据帧来传输一个数据。分片传输分为三个部分:
开始帧:FIN=0,Opcode>0;一个
传输帧:FIN=0,Opcode=0;零个或多个
终止帧:FIN=1,Opcode=0;一个
FIN是FINAL的缩写,它为1时表示一个数据传输结束,而开始和传输帧的时候数据都没结束,所以是0,之后最后的结束帧FIN是1。同一个数据即使分片传输,它的每个数据帧的Opcode也应该相同,为了避免冲突,只对分片传输的开始帧设置Opcode,传输帧和结束帧的Opcode留0。因此把上面实例的部分代码改成
1 2 3 4 5 6 7 8 9 10 | //握手成功后给客户端发送个数据 o.write(encodeDataFrame({ FIN:0,Opcode:1,PayloadData:"ABC" })); o.write(encodeDataFrame({ FIN:0,Opcode:0,PayloadData:"-DEF-" })); o.write(encodeDataFrame({ FIN:1,Opcode:0,PayloadData:"GHI" })); |
就可以在客户端得到

这就是分片传输的关键所在。
转自: https://www.web-tinker.com/article/20307.html
WebSocket(贰) 解析数据帧
知道了怎么握手只是让客户端和服务器建立连接而已,WebSocket真正麻烦的地方是在数据的传输上!为了环保,它使用了特定格式的数据帧,这个数据帧需要自己去解析(当然也有别人编写好的库可以用)。虽然官方文档描述的很详细,但是看起来还是蛋疼。
当客户端向服务器发送一个数据时服务器收到一个数据帧,比如下面的程序
1 2 3 4 5 | //客户端程序 var ws=new WebSocket("ws://127.0.0.1:8000"); ws.onopen=function(e){ ws.send("次碳酸钴"); //发送数据 }; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | //服务器程序 var crypto=require('crypto'); var WS='258EAFA5-E914-47DA-95CA-C5AB0DC85B11'; require('net').createServer(function(o){ var key; o.on('data',function(e){ if(!key){ //握手 key=e.toString().match(/Sec-WebSocket-Key: (.+)/)[1]; key=crypto.createHash('sha1').update(key+WS).digest('base64'); o.write('HTTP/1.1 101 Switching Protocols\r\n'); o.write('Upgrade: websocket\r\n'); o.write('Connection: Upgrade\r\n'); o.write('Sec-WebSocket-Accept: '+key+'\r\n'); o.write('\r\n'); }else onmessage(e); //接收并交给处理函数 }); }).listen(8000); function onmessage(e){ console.log(e); //把数据输出到控制台 }; |
这里是直接把接收到的数据输出了,得到这样一个东西

这就是一个完整的数据帧,直接的16进制数据我们当然无法直接阅读,需要按照数据帧的格式把它里面的数据取出来才行。对于这个数据帧,官方文档提供了一个结构图
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-------+-+-------------+-------------------------------+ |F|R|R|R| opcode|M| Payload len | Extended payload length | |I|S|S|S| (4) |A| (7) | (16/64) | |N|V|V|V| |S| | (if payload len==126/127) | | |1|2|3| |K| | | +-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - + | Extended payload length continued, if payload len == 127 | + - - - - - - - - - - - - - - - +-------------------------------+ | |Masking-key, if MASK set to 1 | +-------------------------------+-------------------------------+ | Masking-key (continued) | Payload Data | +-------------------------------- - - - - - - - - - - - - - - - + : Payload Data continued ... : + - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - + | Payload Data continued ... | +---------------------------------------------------------------+
光拿出这个实在很难看懂,顶部数字用十进制而不是八进制太让人蛋疼了。当然官方文档在后面的描述中也有详细介绍,看完后再回头来看图表才能看明白。其实WebSocket目前还不太完善,很多实验性的东西,所以完全按照官方文档来理解是蛋疼的。这里就说我自己的理解。
现在再看左上角上面的图标,左上角的四个小列,也就是4位,第一位是FIN,后面三位是RSV1到3。官方文档上说RSV是预留的空间,正常为0,这就意味着,正常情况下他们可以当做0填充,那么前4位只有第一位的FIN需要设置,FIN表示帧结束,由于这篇中它不重要就不特别介绍了。接着后面的四位是储存opcode的值,这个opcode是标识数据类型的。这样数据的第一个字节我们就能理解它的含义了,看上面16进制的数据的第一个字节81换成二进制是1000001,第一个1是FIN的值,最后一个1是opcode的值。
接着是第二个字节的数据,它由1位的MASK和7位的PayloadLen组成,MASK标识这个数据帧的数据是否使用掩码,PayloadLen表示数据部分的长度。但是PayloadLen只有7位,换成无符号整型的话只有0到127的取值,这么小的数值当然无法描述较大的数据,因此规定当数据长度小于或等于125时候它才作为数据长度的描述,如果这个值为126,则时候后面的两个字节来储存储存数据长度,如果为127则用后面八个字节来储存数据长度。所以上面的图片第一行的最右侧那块和第二行看起来有些颓然。从我们的示例数据来看,第二个字节的8C中80是最高位为1,这意味着MASK为1,后面的C表示这个数据部分有12个字节。
再接着是上面图表中的MaskingKey,它占四个字节,储存掩码的实体部分。但是只有在前面的MASK被设置为1时候才存在这个数据,否则不使用掩码也就没有这个数据了。看我们的示例数据,由于前面的MASK为1,所以3到6字节的“79 77 3d 41”是数据的掩码实体。
最后是数据部分,如果掩码存在,那么所有数据都需要与掩码做一次异或运算,四个字节的掩码与所有数据字节轮流发生性关系。如果不存在掩码,那么后面的数据就可以直接使用。
这样数据帧就解析完了。下面是我写的数据帧解析的程序,请不要吐槽代码没优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | function decodeDataFrame(e){ var i=0,j,s,frame={ //解析前两个字节的基本数据 FIN:e[i]>>7,Opcode:e[i++]&15,Mask:e[i]>>7, PayloadLength:e[i++]&0x7F }; //处理特殊长度126和127 if(frame.PayloadLength==126) frame.PayloadLength=(e[i++]<<8)+e[i++]; if(frame.PayloadLength==127) i+=4, //长度一般用四字节的整型,前四个字节通常为长整形留空的 frame.PayloadLength=(e[i++]<<24)+(e[i++]<<16)+(e[i++]<<8)+e[i++]; //判断是否使用掩码 if(frame.Mask){ //获取掩码实体 frame.MaskingKey=[e[i++],e[i++],e[i++],e[i++]]; //对数据和掩码做异或运算 for(j=0,s=[];j<frame.PayloadLength;j++) s.push(e[i+j]^frame.MaskingKey[j%4]); }else s=e.slice(i,i+frame.PayloadLength); //否则直接使用数据 //数组转换成缓冲区来使用 s=new Buffer(s); //如果有必要则把缓冲区转换成字符串来使用 if(frame.Opcode==1)s=s.toString(); //设置上数据部分 frame.PayloadData=s; //返回数据帧 return frame; }; |
既然有了解析程序,那么我们就可以把上面实例服务器端的onmessage方法修改一下
1 2 3 4 | function onmessage(e){ e=decodeDataFrame(e); //解析数据帧 console.log(e); //把数据帧输出到控制台 }; |
这样服务器接收客户端穿过了的数据就没问题了。嘛,这篇文章就只说接收,至于从服务器发送到客户的情况会有更复杂的情况出现,咱下一篇再说。
转自: https://www.web-tinker.com/article/20306.html