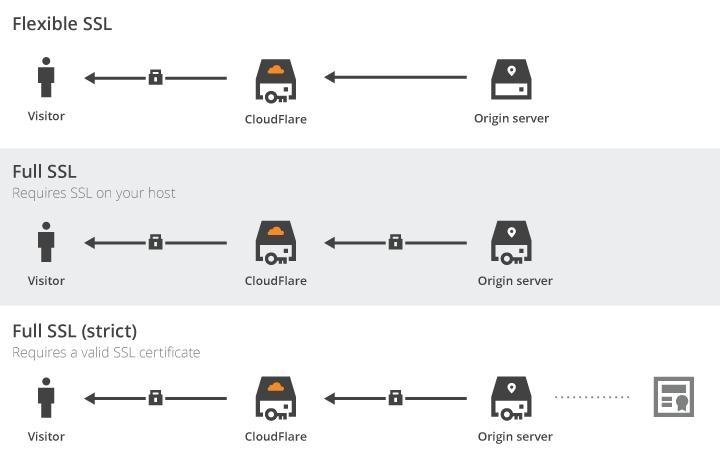
说起 HTTP server,使用最广泛的就是 apache 和 nginx 了,功能都非常强大,但相对而言,学习它们的配置是有一定难度的。最近发现了一个 golang 开发的 HTTP server,叫做 Caddy,它配置起来十分简便,甚至可以 28 秒配置好一个支持 http2 的 server ,而且对各种 http 新特性都支持的比较早(比如 http2、quic都有支持)。因此对于不用于生产环境只搭建个人博客是十分友好的,我就简单介绍下 caddy。
Caddy – 方便够用的 HTTPS server 新手教程
aa
1. 安装
用过 golang 的应该都知道,golang 程序基本上不会有各种依赖,都是光秃秃一个可执行程序,cp 到 /usr/local/bin就算安装完成了,所以说安装 caddy 是很简单的,我给出三种方法。
1.1 脚本安装
curl -s https://getcaddy.com | bash
caddy 官方给出了一个安装脚本,执行上面的命令就可以一键安装 caddy,等执行结束后,使用 which caddy,可以看到 caddy 已经被安装到了 /usr/local/bin/caddy
1.2 手动安装
https://caddyserver.com/download 点这个链接进入到 caddy 官网的下载界面,网页左侧可以选择平台和插件,如果在 Linux 服务器上使用的话,platform 选择 Linux 64-bit 就可以了,plugins 如果暂时不需要的话,可以不选。然后点击下面的 DOWNLOAD 按钮,就下载到 caddy 了。同理,解压之后用 cp 命令放到 /usr/local/bin/caddy 就完成了安装。

1.3 源码安装
go get github.com/mholt/caddy/caddy
对于安装了 golang 编译器的同学,只需要执行 go get 就能到 $GOPATH/bin 里,是否 cp 到 /usr/local/bin 里就看心情了。使用源码安装可以安装到最新版本的 caddy,功能上一般是最新的,而且因为是本地编译,性能可能会稍微高一些,但是可能会存在不稳定的现象。
2. 配置
2.1 临时文件服务器
Caddy 的配置文件叫做 Caddyfile,Caddy 不强制你把配置文件放到哪个特定文件夹,默认情况下,把 Caddyfile 放到当前目录就可以跑起来了,如下:
echo 'localhost:8888' >> Caddyfileecho 'gzip' >> Caddyfileecho 'browse' >> Caddyfilecaddy
在随便一个目录里执行上面代码,然后在浏览器里打开 http://localhost:8888 发现 caddy 已经启动了一个文件服务器。当临时需要一个 fileserver 的时候(比如共享文件),使用 caddy 会很方便。
2.2 生产环境使用
当然了,在生产环境使用的时候就不能这么草率的把配置文件放到当前目录了,一般情况下会放到 /etc/caddy 里。
sudo mkdir /etc/caddysudo touch /etc/caddy/Caddyfilesudo chown -R root:www-data /etc/caddy
除了配置文件,caddy 会自动生成 ssl 证书,需要一个文件夹放置 ssl 证书。
sudo mkdir /etc/ssl/caddysudo chown -R www-data:root /etc/ssl/caddysudo chmod 0770 /etc/ssl/caddy
因为 ssl 文件夹里会放置私钥,所以权限设置成 770 禁止其他用户访问。
最后,创建一下放置网站文件的目录,如果已经有了,就不需要创建了。
sudo mkdir /var/wwwsudo chown www-data:www-data /var/www
创建好这些文件和目录了之后,我们需要把 caddy 配置成一个服务,这样就可以开机自动运行,并且管理起来也方便。因为目前大多数发行版都使用 systemd 了,所以这里只讲一下如何配置 systemd,不过 caddy 也支持配置成原始的 sysvinit 服务,具体方法看这里。
sudo curl -s https://raw.githubusercontent.com/mholt/caddy/master/dist/init/linux-systemd/caddy.service -o /etc/systemd/system/caddy.service # 从 github 下载 systemd 配置文件sudo systemctl daemon-reload # 重新加载 systemd 配置sudo systemctl enable caddy.service # 设置 caddy 服务自启动sudo systemctl status caddy.service # 查看 caddy 状态
3. Caddyfile
基本的安装配置搞定之后,最重要的就是如何写 Caddyfile了。可以直接 vim /etc/caddy/Caddyfile 来修改 Caddyfile,也可以再自己电脑上改好然后 rsync 到服务器上。如果修改了 Caddyfile 发现没有生效,是需要执行一下 sudo systemctl restart caddy.service 来重启 caddy 的。
3.1 Caddyfile 的格式
Caddfile的格式还是比较简单的,首先第一行必须是网站的地址,例如:
localhost:8080
或
lengzzz.com
地址可以带一个端口号,那么 caddy 只会在这个端口上开启 http 服务,而不会开启 https,如果不写端口号的话,caddy 会默认绑定 80 和 443 端口,同时启动 http 和 https 服务。
地址后面可以再跟一大堆指令(directive)。Caddyfile 的基本格式就是这样,由一个网站地址和指令组成,是不是很简单。
3.2 指令
指令的作用是为网站开启某些功能。指令的格式有三种,先说一下最简单的不带参数的指令比如:
railgun.moe # 没错,moe后缀的域名也可以哦gzip
第二行的 gzip 就是一个指令,它表示打开 gzip 压缩功能,这样网站在传输网页是可以降低流量。
第二种指令的格式是带简单参数的指令:
railgun.moegziplog /var/log/caddy/access.logtls lengz@lengzzz.comroot /var/www/
第三行,log 指令会为网站开启 log 功能,log 指令后的参数告诉 caddy log 文件存放的位置。第四行的 tls 指令告诉 caddy 为网站开启 https 并自动申请证书,后面的 email 参数是告知 CA 申请人的邮箱。(caddy 会默认使用 let’s encrypt 申请证书并续约,很方便吧)
另外,简单参数也可能不只一个,比如 redir 指令:
railgun.moegziplog /var/log/caddy/access.logtls /etc/ssl/cert.pem /etc/ssl/key.pemroot /var/www/redir / https://lengzzz.com/archive/{uri} 301
上面的 redir 指令带了三个参数,意思是把所有的请求使用 301 重定向到 https://lengzzz.com/archive/xxx,这个指令在给网站换域名的时候很有用。另外 tls 指令变了,不单单传 email一个参数, 而是分别传了证书和私钥的路径,这样的话 caddy 就不会去自动申请证书,而是使用路径给出的证书了。
在这个例子里还使用了 {uri} 这样的占位符(placeholder),详细的列表可以在这里查询到:https://caddyserver.com/docs/placeholders。
最后一种指令是带复杂参数的,这种指令包含可能很多参数,所以需要用一对花括号包起来,比如 header 指令:
railgun.moegziplog /var/log/caddy/access.logtls lengz@lengzzz.comroot /var/www/header /api { Access-Control-Allow-Origin * Access-Control-Allow-Methods "GET, POST, OPTIONS" -Server}fastcgi / 127.0.0.1:9000 php { index index.php}rewrite { to {path} {path}/ /index.php?{query}}
6-10 行的 header 指令代表为所有的 /api/xxx 的请求加上 Access-Control-Allow-Origin 和 Access-Control-Allow-Methods 这两个 header,从而能支持 javascript 跨域访问 ,第 9 行代表删除 Server header,防止别人看到服务器类型。
11-13 行使用了 fastcgi 指令,代表把请求通过 fastcgi 传给 php,ruby 等后端程序。
14-15 行,使用了 rewrite 指令,这个指令的作用是 服务器内部重定向 在下面的参数 to 后面,又跟了三个参数,这个功能上有点类似 nginx 的 try_files 。告诉 caddy 需要先查看网址根目录 /var/www 里有没有 {path} 对应的文件,如果没有再查看有没有 {path} 对应的目录,如果都没有,则转发给 index.php 入口文件。这个功能一般会用在 PHP 的 MVC 框架上使用。
随着一步步完善这个 Caddyfile,目前这个版本的 Caddyfaile 已经可以直接在网站中使用了。
3.3 多 HOST 网站
刚才说的一直都是单个域名的网址,那么如果在同一个服务器上部署多个域名的网站呢?很简单,只需要在域名后面跟一个花括号扩起来就可以了,如下:
railgun.moe { gzip log /var/log/caddy/railgun_moe.log tls lengz@lengzzz.com root /var/www/ header /api { Access-Control-Allow-Origin * Access-Control-Allow-Methods "GET, POST, OPTIONS" -Server } fastcgi / 127.0.0.1:9000 php { index index.php } rewrite { to {path} {path}/ /index.php?{query} }}lengzzz.com { tls lengz@lengzzz.com log /var/log/caddy/lengzzz_com.log redir / https://railgun.moe/{uri} 301}
好了,基本的 caddy 配置就这些,详细的内容可以去官网上看文档学习。
https://caddyserver.com/docs
转自: https://lengzzz.com/note/caddy-http-2-web-server-guide-for-beginners